
Many businesses and marketers already implement on-page content-focused SEO tactics like writing search-friendly titles and meta descriptions and optimizing content around keywords. However, the success of these strategies also hinges on a critical but often misunderstood aspect of SEO: technical SEO.
What is Technical SEO?
Technical SEO (search engine optimization) involves optimizing a website’s code and structure to make it more search engine-friendly and user-friendly, thus improving its chances of ranking higher in search results.
Technical SEO works by focusing on the backend elements of a website, like:
- Fixing broken links and 404 errors
- Creating an internal linking structure to improve website navigation and distribute link equity
- Testing mobile usability and fixing issues that can hinder mobile users’ experience
- Optimizing images and media files to reduce file size and improve load times
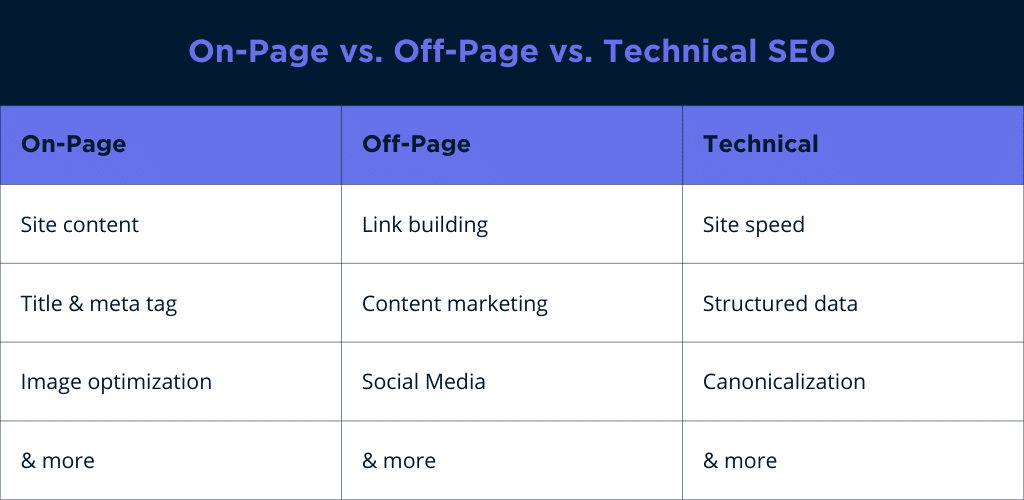
On-Page (Content) vs. Off-Page vs. Technical SEO
There are three primary aspects of SEO, each serving an important purpose.
On-page SEO
Optimizing your web pages with relevant content that tells users and search engines what your content is about.
Example: Optimizing a blog post with target keywords, well-structured headings, and relevant meta tags.
Off-page SEO
Using external strategies to enhance a website’s authority, reputation, and relevance in search engines through backlinks, social signals, and brand mentions.
Example: Building backlinks from reputable websites to increase the site’s credibility.
Technical SEO
Optimizing your website’s backend and infrastructure to improve its crawlability, indexability, and overall performance.
Example: Implementing structured data markup to enhance search engine understanding of product information.
Why Technical SEO Is Important
While content and off-page SEO factors are important, neglecting technical SEO can undermine all other efforts.
If search engines can’t access your web pages, users can’t find them, no matter how optimized your site is with relevant keywords and image alt tags.
💻 Why is technical SEO important for any website?
“Technical SEO is one of the pillars of SEO and is arguably the most important since it impacts crawlability. Making sure your website is technically sound helps to ensure that crawlers can crawl it effectively and efficiently. Without a strong technical foundation, easy crawlability, indexation and ranking becomes harder and harder.”
–Hayley Zakaria, SEO Lead, Harley-Davidson Motorcycle Company
Fast-loading pages, easy navigation, and mobile-friendliness keep visitors engaged and encourages them to spend more time on your site.
If a user encounters a 404 error when clicking on your blog post, they will quickly bounce to another website. This signals to search engines your site provides a negative user experience, potentially lowering your search engine rankings and authority score.
💻 Why is technical SEO so important?
“Even the best, most captivating content could be doomed to obscurity without a basic technical SEO foundation.”
–Chris Chapa, Director Global SEO, Footlocker
How Technical SEO Works
There are two essential parts to technical SEO:
- Crawlability: The ability of search engine bots to access and navigate a website’s pages.
- Indexability: Determines whether a website’s pages will be included in search engine indexes and appear in search results.
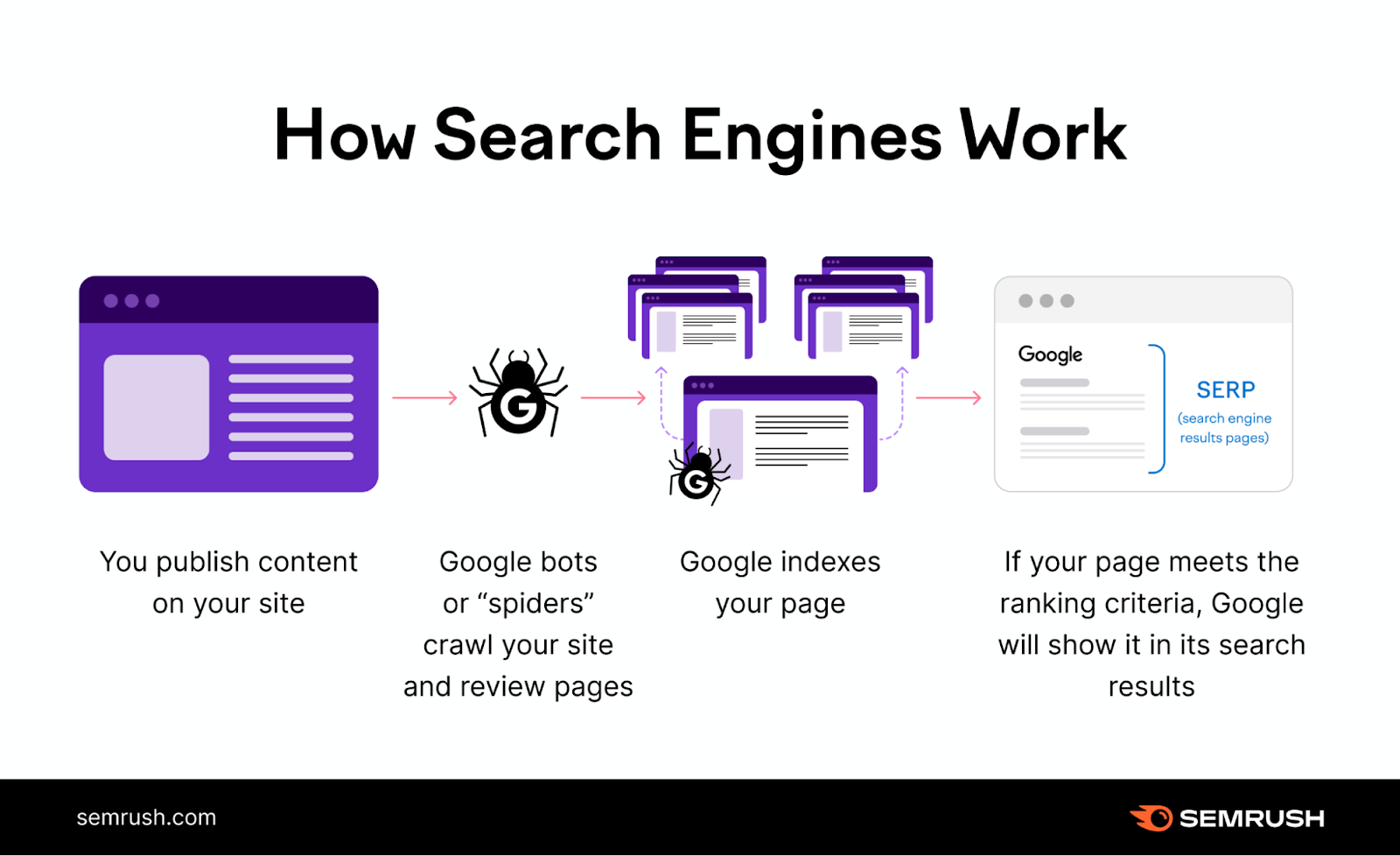
How Crawling Works
Imagine tiny robots that visit web pages. They explore the internet, visit web pages, and collect information to help search engines show you the most relevant and updated results when you search for something.
Here’s how it works:
1. The Search Engine Robots Start Their Journey
The search crawlers, called bots or spiders, begin by visiting a few websites they already know.
Example: Let’s say the bots start at a website called www.yoursite.com and find links to other pages like www.yoursite.com/blog and www.yoursite.com/contact.
2. The Bots Discover New Paths
When the bots are on a webpage, they look for other links that take them to more web pages. It’s like discovering new paths to explore.
Example: The bots find links on www.yoursite.com that lead them to www.yoursite.com/blog and www.yoursite.com/contact. These new pages become the next destinations for the bots’ adventure.
3. Prioritizing Important Places
Bots navigate by following links, which enables them to explore a large number of web pages. However, search engines like Google are less likely to discover and index pages that are not linked to frequently or at all (called orphaned pages).
Example: If www.yoursite.com/blog is a popular page, but pages don’t link to it, the bots may not fix it or index it.
4. The Bots Collect Information
When the bots visit a webpage, they note what they find. They read the words, look at the pictures, and even check the page’s structure and code.
Example: If www.yoursite.com/blog/10-seo-tips is a blog post about “Top 10 SEO Tips,” the bots read the blog post, look for the main points, and remember it for later.
5. Keeping Everything Up to Date
The bots don’t just visit a webpage once and forget about it. They come back regularly to see if anything has changed. This way, they can keep their indexed information fresh.
Example: If www.yoursite.com/blog is a news website with new stories every hour, the bots will often return to get the latest news for their library.
For example, when we post a blog post, we add them to our news section on our website.
The bots will notice new links to our blog posts during their next crawl, helping Google discover our latest content. This is only one of a few ways Google finds new links, which is why it’s important search engines can access your pages.
💡 What is a common issue that can prevent a page from being crawled?
“The most obvious but often ignored reason a page may not be crawled is that you’re not linking to it. This is the first thing an SEO should check when diagnosing crawlability issues. It may seem obvious, but sometimes the essentials like linking to a page are forgotten.”
–Hayley Zakaria, SEO Lead, Harley-Davidson Motorcycle Company
To learn how to make your website accessible for search engines, including a linking structure, skip ahead here.
How Indexing Works
After the search engine bots crawl a web page and gather information about its content, they index it in their database. This database acts like a massive library catalog containing details about all the web pages on the internet.
Here’s how indexing works:
1. Organizing the Information
After the bots finish their crawling journey and visit web pages, they return with notes and details about what they found on your website, www.yoursite.com/blog.
However, the search engine needs a way to keep all this information organized, much like a librarian needs a catalog to find books.
Example: If the bots crawled your blog page www.yoursite.com/blog, they would have collected information about the blog’s title, content, keywords, and other important details.
2. Creating the Library Catalog
The search engine creates an extensive library catalog called the “index.” This catalog contains all the information the bots collected during their crawling adventure on your site.
The index stores details about each web page found on “www.yoursite.com/blog, so it’s quick and easy to find things later.
Example: In the index, the search engine keeps track of www.yoursite.com/blog and everything the bots learned about it, like the blog’s topic, the words it contains, and how relevant it is to different search queries.
3. Retrieving Information When You Search
When you search for something on the internet, the search engine uses its index to find the most relevant web pages. It flips through the catalog for web pages that match your search query and ranks them based on how well they fit what you’re looking for.
Example: If you search for “SEO Services in Detroit” and your blog post on www.yoursite.com/blog/seo-services-detroit has information about on-page SEO services for local Detroit businesses, the search engine uses its index to find your blog and shows it to users searching for the query.
4. Keeping the Library Up to Date
Like a library keeps adding new books, the search engine keeps its index fresh and current. The bots regularly crawl web pages repeatedly to find new information and update the index accordingly.
Example: If you update your blog post, www.yoursite.com/blog/seo-services-detroit, with new services or changing prices, the bots will crawl it again and update the index with the latest information.
To learn how to make your site indexable and fix common indexing problems, skip ahead here.
🔍 Hire a Technical SEO Agency.
Our team of SEO experts has the right tools and support you need to attract more leads and sales.
Technical SEO Basics & Strategies
Now that you understand how search engines crawl and index your web pages, we’ll review some technical SEO basics and strategies you can try out today.
1. Make Your Website Accessible For Search Engine Crawlers
You want crawlers to access your web pages or else they won’t organize them for search engines. Here are a few ways to make sure they can find your pages:
1. Build SEO-Friendly Site Structure
Site structure or site architecture is how your pages link together within your site. Executed successfully, it’s a well-organized roadmap of your website, guiding search engine crawlers and visitors through your website’s content quickly and easily.
Your web pages should be only a couple clicks away from your homepage.
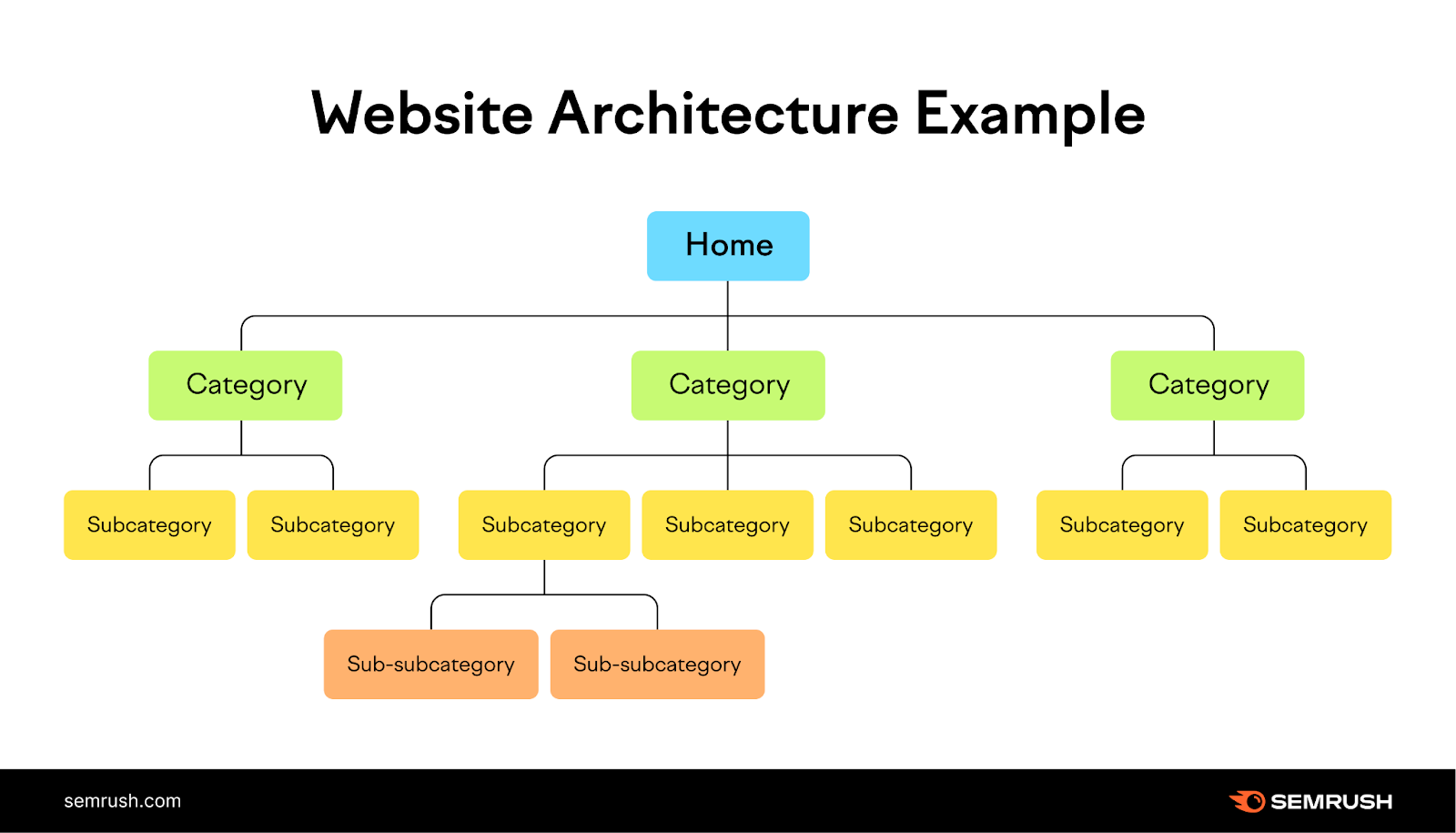
As you can see, all the pages above are organized in a logical hierarchy starting from your homepage and broken down into smaller categories called “subpages.”
⚡ 94% of surveyed users consider easy navigation the most important website element.
To do this, divide your website content into logical categories and subcategories. Here’s how Ulta organizes its website:
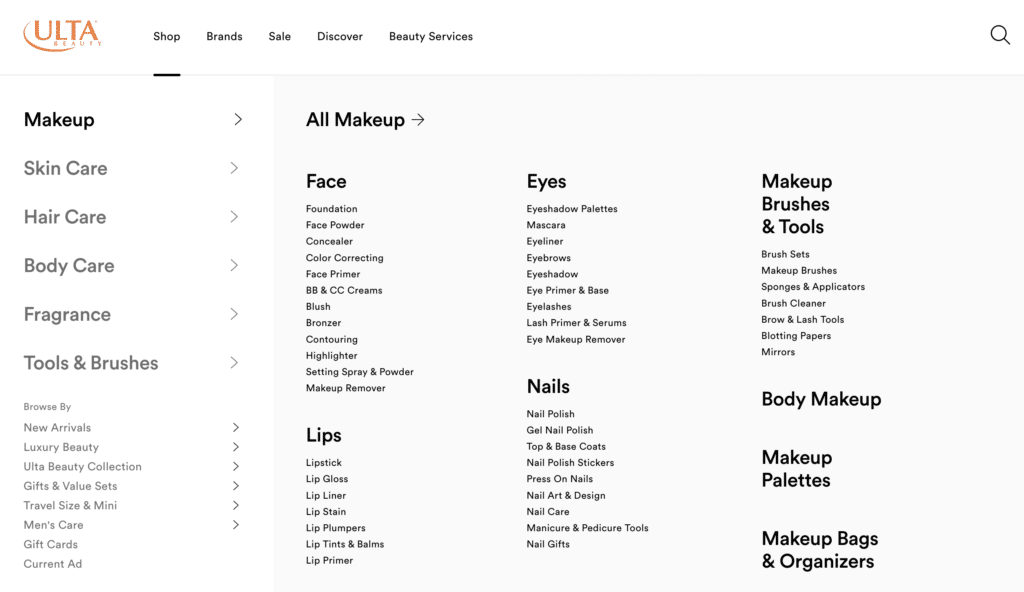
Ulta’s user-friendly navigation menu organizes products into familiar categories, like Makeup, then subcategories, like Face, Eyes, and so forth. This thoughtful arrangement allows shoppers to find desired products with just a few clicks easily.
A well-organized site structure also reduces the number of orphan pages on your website. Orphan pages are pages with no internal links pointing to them. As we know, bots use your pages to find links to other pages. If a page doesn’t have a link pointing to it, bots may be unable to find it.
Add internal links on non-orphan pages linking to the orphaned page to fix this.
2. Submit a Sitemap Structure to Google
A sitemap is a file that lists all the important pages and content on your website hierarchically. Sitemaps are crucial for larger websites or those with complex navigation because it helps crawlers access the pages quickly.
⚡ XML vs. HTML Sitemap
There are two types of sitemap: XML and HTML. An XML sitemap is designed for search engine crawlers, while an HTML sitemap is for users, providing an organized list of links to all pages on your site.
To create an XML sitemap for crawlers, you can do one of three things:
- Let your CMS generate a sitemap for you.
- For sitemaps with fewer than a dozen URLs, manually create one.
- For sitemaps with more than a few dozen URLs, automatically generate one.
Then, you’ll submit your sitemap to Google in Google Search Console (GSC), you can follow Google’s instructions.
💡 Tip: Whenever you add new content, remove old pages, or make significant changes, update your sitemap accordingly. Keeping it up-to-date helps search engines quickly discover fresh content.
3. Use Robots.txt
The robots.txt file can control which parts of your site crawlers can access. It’s placed in your website’s root directory and uses simple commands like “Allow” and “Disallow” to specify where the bots can and cannot go.
Example:
User-agent: *
Disallow: /private/
Disallow: /admin/
Disallow: /login/
Sitemap: https://www.example.com/sitemap.xml
In this example, bots are disallowed from accessing the website’s /private/, /admin/, and /login/ directories. The also includes your website’s Sitemap so the bots can find all your important web pages faster.
Here’s an example of Nike’s robots.txt file–”just crawl it!”:
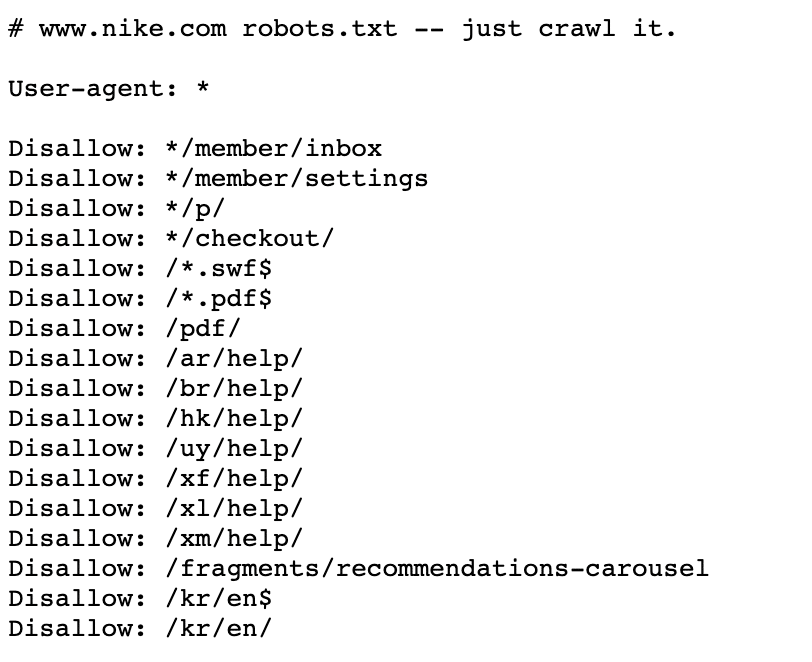
💡 Tip: Robots.txt can guide search engine crawlers but isn’t fully secure for sensitive content. Malicious bots may not follow it, so use additional security measures (e.g., password protection, user authentication, HTTPS encryption, etc) alongside robots.txt.
4. Add Internal Links
Internal linking involves connecting different pages and content within your website. When search engine bots crawl your site, they follow these internal links to discover new pages and content.
This is what an internal link looks like on our website:

Our article “Interactive CTV Ads are the Secret to Higher Engagement” links out to another relevant article on our site, “What are Connected TV (CTV) and Over-The-Top (OTT)?”.
Internal links do three primary things:
- Help bots understand site structure: links guide search engine bots through your website’s organization and hierarchy.
- Distribute website authority: linking pages within your site shares SEO value, signaling to search engines the importance of specific pages or PageRank.
- Improve user navigation: links create smooth pathways for users, making exploring and finding relevant content on your website easier.
To add internal links across your website, you’ll want to:
- Use relevant anchor text: Use descriptive and relevant anchor text (the clickable text of a link) that provides a clear indication of the linked page’s content. Avoid generic phrases like “click here” and instead use keywords that reflect the linked page’s topic.
- Link to relevant content only: Point to related and contextually appropriate content. If your article is on rich media advertising, but it links to an irrelevant page on technical SEO best practices, it can confuse both users and search engines.
- Avoid overlinking: Excessively linking can be overwhelming for users. Each link should provide valuable information for the readers.
- Update old content: Regularly review and update your internal links, especially within older blog posts or pages. If new, more relevant content is available, link to it instead of outdated pages.
💡 Tip: Try to add at least 4-5 internal links to new blog posts. Also, when you add an internal link, only use it once in the post as using it multiple times may dilute its impact and confuse readers.
2. Make Your Website Indexable
A couple of factors can prevent search engines from indexing your web pages:
1. Check for Noindex Tags
The “noindex” tag communicates to search engines, particularly Google, that you do not want a specific page in their index.
Placing this HTML snippet within your webpage’s <head> section prevents search engine bots from crawling and indexing that page.
Example: <meta name=”robots” content=”noindex”>
Ideally, you want all of your essential pages indexed so search engines can find them. However, it’s useful when you have content that you want to keep hidden from search results, like:
- draft pages
- thank-you pages
- landing pages for PPC ads
- private content not meant for public viewing
💡 What common issue can prevent a page from being indexed?
“If a page of mine is crawled but not indexed, I’ll first see if a “noindex” tag was appended to it. This directive tells search engines that it shouldn’t index the page, preventing it from appearing in the SERP. I find that developers sometimes add this tag to a page while it’s in staging and forget to remove it once pushing it into production. So once escalated, this can usually get removed pretty quickly.”
–Hayley Zakaria, SEO Lead, Harley-Davidson Motorcycle Company
2. Use Canonical Tags
Crawlers may miss your site if they find similar content on multiple pages, potentially interpreting them as separate pages and splitting ranking authority.
Canonicalization tells search engines which URL represents a page’s main, original, or “canonical” version to avoid duplicate content issues and consolidate ranking signals.
To implement canonicalization, SEOs, and webmasters use a special HTML tag called the “canonical tag” (rel=”canonical”) in the <head> section of the preferred URL.
Example: if you have multiple URLs pointing to the same content like www.yoursite.com/blog, yoursite.com/blog, and www.yoursite.com/blog/?id=521, you can use the canonical tag on www.yoursite.com/blog to indicate that it’s the preferred version:
<link rel=”canonical” href=”https://www.yoursite.com/blog“>
3. Check Your Site Speed/Core Web Vitals
Google’s Core Web Vitals are user-centered site speed metrics. They measure the speed, responsiveness, and visual stability of your web page.
The Core Web Vital metrics include:
- Largest Contentful Paint (LCP): Measures how long it takes for the largest content element (such as an image or text block) on a web page to become visible to the user.
- First Input Delay (FID): Measures the time it takes for a web page to respond to the first user interaction, such as clicking a link or tapping a button.
- Interactive to Next Paint (INP): Measures the time it takes for the page to respond to all user clicks, taps, and keyboard interactions occurring throughout a user’s page visit.
- Cumulative Layout Shift (CLS): Evaluates a web page’s visual stability by measuring unexpected layout shifts during its loading process.
Google considers these Core Web Vitals important for ranking web pages in its search results, especially for mobile searches. Websites that offer a better user experience by meeting or exceeding the recommended thresholds for these metrics are more likely to rank higher in Google’s search results.
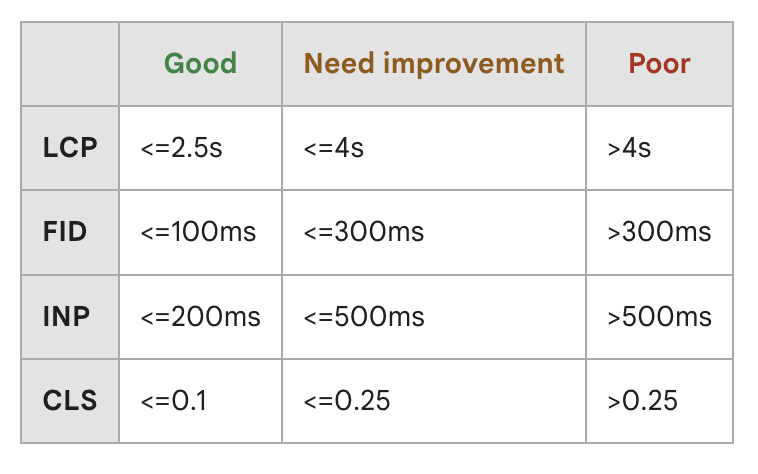
This chart shows the performance ranges for each vital.
5. Make Sure Your Website Design is Mobile-First
Google uses mobile-first indexing, prioritizing mobile versions of web pages to index and rank content. Also, more than ever, searchers primarily use mobile devices to search for content.
⚡ In 2023, mobile devices accounted for 58% of website traffic worldwide.
So, you’ll want a mobile-friendly site design.
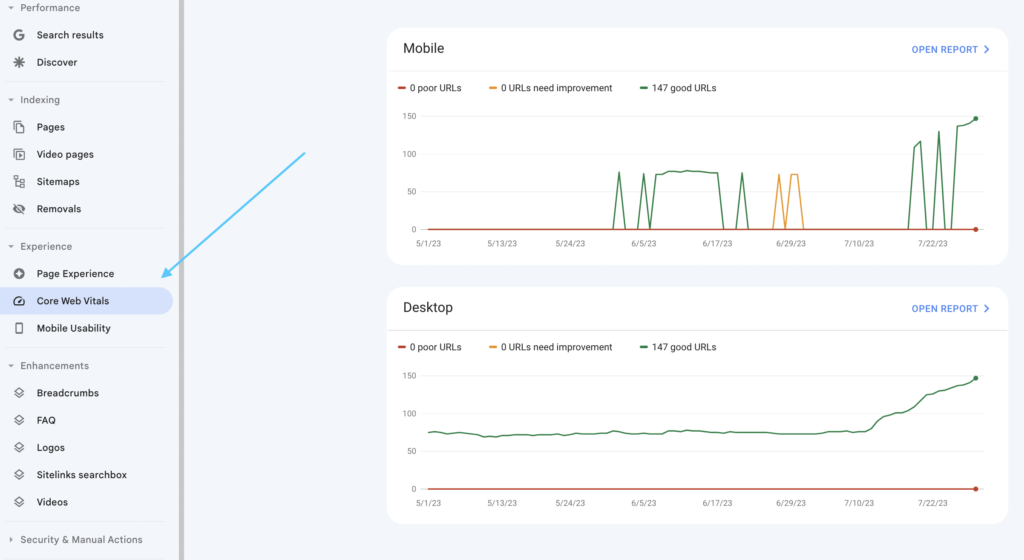
Google can check if your web page is mobile-friendly. Type your URL in and click Test URL.
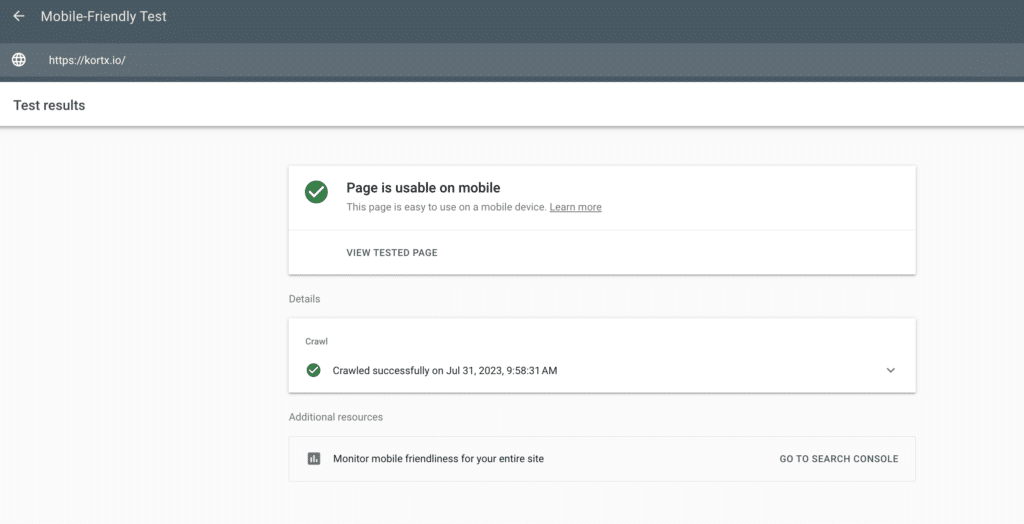
You can also view the Mobile Usability report in Google Search Console. The report shows you how many of your pages affect mobile usability and specific issues to correct.
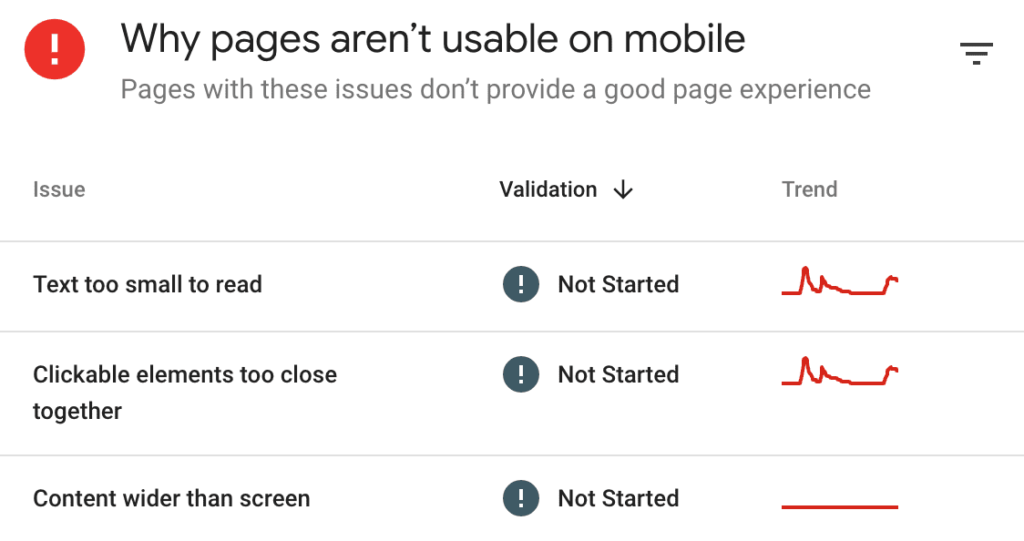
❗On December 1, 2023, Google will sunset both the usability report, the mobile-friendly tool, and the mobile-friendly API. Instead, Google recommends other resources to evaluate mobile usability, including Chrome’s Lighthouse extension.
6. Add Schema Markup To Your Website’s Code
Schema markup, or structured data, is code added to a website’s HTML that provides search engines with explicit information about the page’s content.
This improves how search engines understand your web pages and increase your real estate in the search results like this:
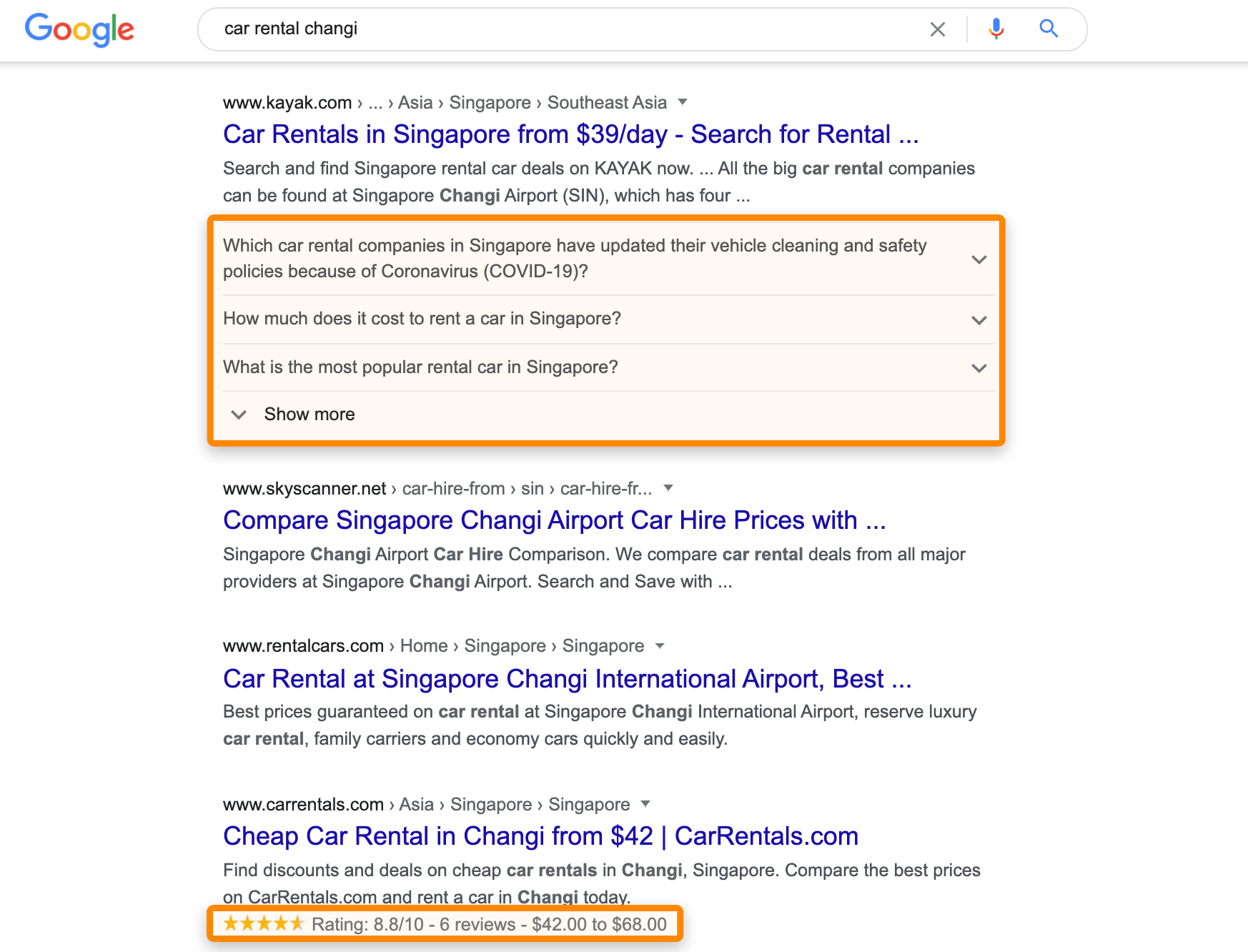{kind=link}
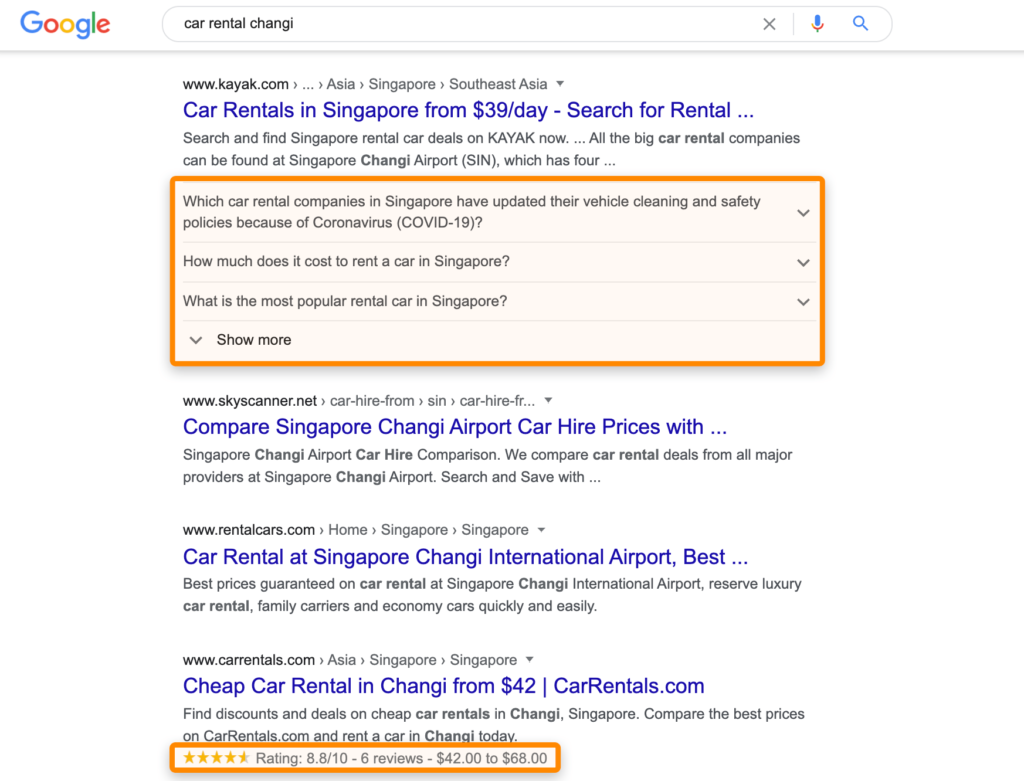
Schema makes your pages stand out from other pages, enticing users to click through to your website.
Google supports dozens of schema markups to add to your website. You’ll want to pick the most suitable schema type that aligns with your website’s content, such as Article, Product, LocalBusiness, or more.
To generate schema markup, you can use a manual tool like Merkle. It will guide you through your input values and generate a code to copy.
Or ChatGPT can generate your schema markup. Just feed it a prompt starting with “Write JSON-LD structured data for [insert what schema you want here].
For an FAQ schema, we asked ChatGPT to write it for FAQs and provided the values:
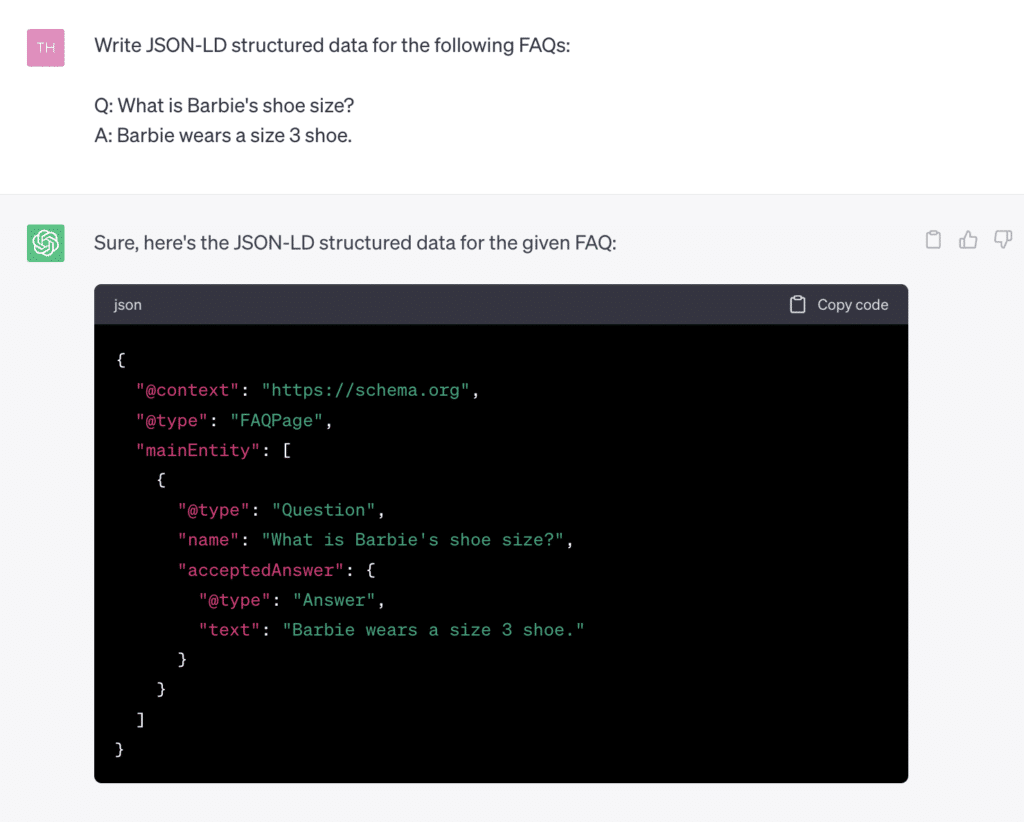
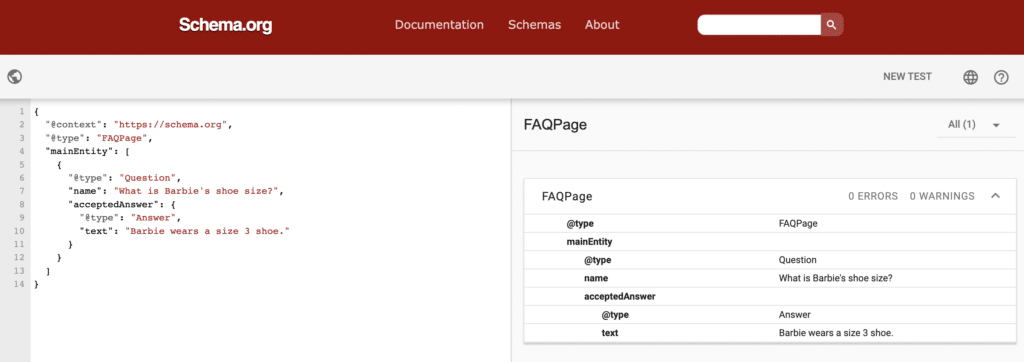
Then, test your code with Google’s Schema Markup Validator. Select the Code Snippet option. Paste your code snippet in the box and select Run Test.
Once you generate the schema, you’ll paste it into the <head> section of your website’s HTML code. This location is most recommended so search engines can easily find it.
7. Find and Fix Broken Pages
Broken pages negatively affect the user experience. When a user clicks on your page and the page is broken, they’ll likely bounce to another website to get the information they need.
Use website crawling tools like Screaming Frog, Lumar’s DeepCrawl, Semrush’s Site Audit tool, or Google Search Console to scan your site thoroughly. The crawl results will identify pages with broken links, 404 errors, or other issues.
To fix these, consider a few solutions:
- Reinstate the page that was deleted.
- Redirect older posts with backlinks to other relevant pages.
To redirect the page, look and choose a page on your website covering similar or related topics to the removed page. Then, set up a redirect from the broken URL to the replacement page.
📚 Since redirects can be complicated, here’s a guide from Semrush to help you set up a URL redirection.
Resources to Get You Started
Here are some top-notch technical SEO resources to help you get started on the right foot:
- Semrush Blog: Semrush is a widely recognized SEO tool, but their blog is equally valuable for learning about technical SEO concepts.
- Google Search Central: When it comes to SEO, there’s no better source than the official word from Google itself.
- Screaming Frog Blog: Screaming Frog is an SEO spider tool, and their blog delves into technical SEO insights and hands-on tutorials.
- Backlinko: Brian Dean, the founder of Backlinko, provides high-quality and actionable content through his blog and videos.
🔍 SEO is tricky. You need an expert.
Whether you’re a small SaaS company or an established B2B brand, we have experience across all industries. With our expertise, you’ll get tailored SEO strategies that drive targeted traffic, increase conversions, and improve your online presence.
Josh Pettovello is a University of Michigan graduate who enjoys all things data, SEO, and nerding out.